A Comparative Analysis of Mistral 7B, GPT-3.5, and GPT-4.o using the Crew AI Framework
A Comparative Analysis of Mistral 7B, GPT-3.5, and GPT-4.o using the Crew AI FrameworkContinue reading on Medium » Read More Python on Medium
#python
IT, Techno, Auto, Bike, Money
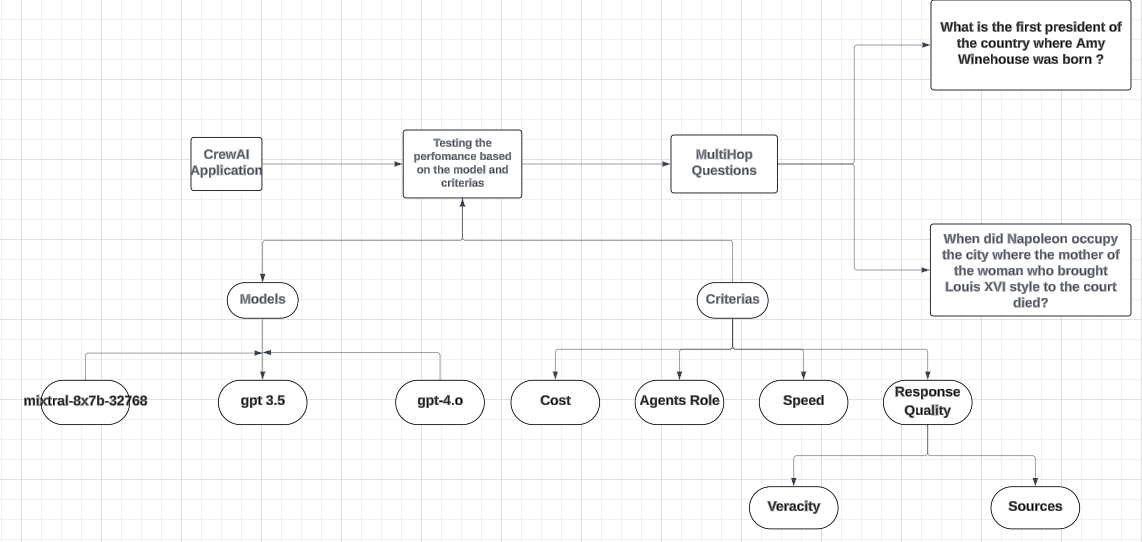
A Comparative Analysis of Mistral 7B, GPT-3.5, and GPT-4.o using the Crew AI Framework
A Comparative Analysis of Mistral 7B, GPT-3.5, and GPT-4.o using the Crew AI FrameworkContinue reading on Medium » Read More Python on Medium
#python