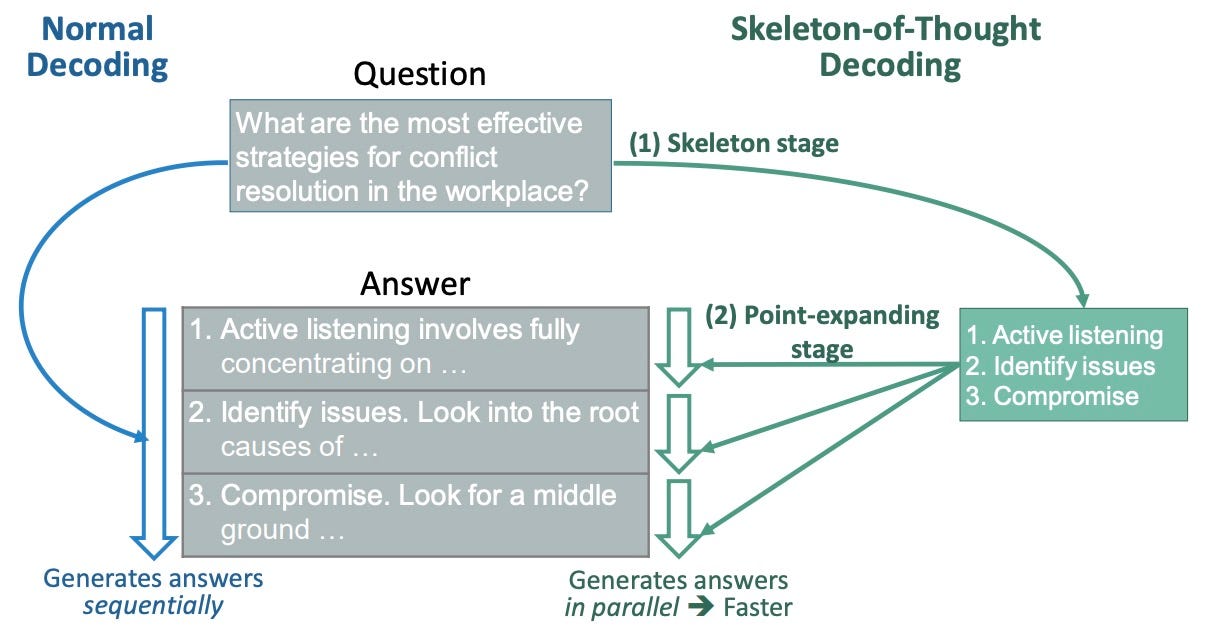
Large language models (LLMs) are revolutionizing technology, but their speed can be a major bottleneck. This is especially true in…
Large language models (LLMs) are revolutionizing technology, but their speed can be a major bottleneck. This is especially true in…Continue reading on Python in Plain English » Read More Llm on Medium
#AI